Engineering Determinism in AI Systems — Techniques and Frameworks

Recap: The Case for Consistency
In Part 1, we explored why deterministic behavior is essential for trustworthy AI. We established that while consumer AI benefits from creativity, public-sector AI demands reliability. If an eligibility engine interprets income verification differently on Friday than it did on Monday, trust in the system collapses.
Part 2 moves from theory to application. This guide details the concrete engineering techniques required to make AI outcomes consistent, explainable, and defensible.
1. The Anatomy of Instability: Where Randomness Enters
Before we can fix variability, we must identify where it originates. A deterministic system must manage four distinct entry points for randomness:
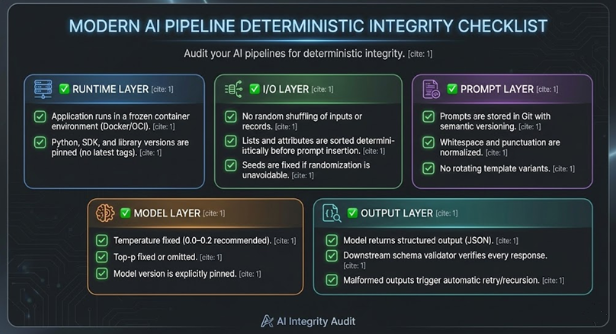
Pre-Processing Logic: Randomly shuffling records or selecting few-shot examples before the prompt is even built .
Prompt Construction: Dynamic formatting or alternating between different template versions.
Model Sampling: The temperature and top-p settings that control how the model chooses the next token.
Execution Environment: Differences in library versions, API serialization, or hardware architecture .
A reproducible system is only as stable as its loosest layer—miss one, and variability creeps in.
2. The Solution: The Reproducibility Stack
Building deterministic AI is less about a single control and more about a layered architecture—what we call the Reproducibility Stack. Each layer tightens the degree of control over model behavior.
To achieve stability, we apply specific engineering controls at every layer of this stack.
3. Engineering Determinism: 5 Core Techniques

Technique 1: Deterministic Pre-Processing (The I/O Layer)
Your application may introduce randomness before the prompt is created. Common culprits include shuffling input records, randomly sampling few-shot examples, or rotating between template variations .
The Fix: Make preprocessing deterministic by eliminating randomness or fixing the seeds for operations that require it.
Implementation: If you must use randomization (e.g., to select examples), you must initialize the seed within the scope of that specific transaction. The goal is for the exact same prompt string to be sent to the model every time.
Technique 2: Normalize Prompts (The Prompt Layer)
Prompts must be stable, predictable, and reproducible. Even minor variations—extra whitespace, alternate casing, or reordered lists—can result in different outputs.
Prompt Normalization Practices:
Immutable Artifacts: Treat prompts as immutable system artifacts once deployed, storing them as version-controlled templates.
Strict Formatting: Normalize whitespace, Unicode characters, and punctuation.
Deterministic Sorting: Always sort lists and structured inputs (e.g., alphabetizing a list of evidence) before inserting them into the prompt.
Technique 3: Constrain Sampling (The Model Layer)
The primary levers for controlling variability in LLM outputs are temperature and top-p.
Temperature Guidelines for Government AI:
0.0: Fully deterministic; always selects the highest-probability token.
0.0–0.2: Recommended for compliance, eligibility evaluation, and policy-driven tasks.
0.5+: Creative and less predictable; generally unsuitable for strict compliance work.
Technique 4: Enforce Structured Output & Recursion (The Output Layer)
For deterministic workflows, it is critical to enforce consistent structure, such as JSON, to prevent drift in formatting .
The Standard Validator: A downstream JSON Schema validator should be used to verify every model response, reject invalid structures, and automatically retry malformed outputs .
Advanced Technique: Recursive Result Checking Validation alone identifies errors; recursive checking fixes them. This creates a "self-healing" loop:
Generate: The model produces a response.
Validate: The system checks the output against the schema.
Recurse: If an error is found (e.g., "Missing Field: Eligibility_Date"), the error is fed back to the model as a new prompt: "You missed the eligibility date. Please correct."
Correct: The model regenerates the valid JSON before it ever reaches the user.
Technique 5: Freeze the Environment (The Runtime Layer)
Although inference often runs on remote servers, your application environment determines how requests are serialized and constructed.
Environment Freezing Practices:
Containerization: Use Docker or OCI container images to ensure the OS and runtime are identical across deployments.
Pin Dependencies: Pin the specific versions of Python, the OpenAI/Model SDK, and all libraries .
Configuration: Capture all settings through environment variables to prevent hidden defaults from changing behavior.
4. Versioning and Governance
Determinism isn’t achievable without governance discipline. You must track the "Chain of Custody" for every AI output.
Model Registry: Maintain a registry recording the model name, provider, version, temperature, seed, and prompt hash.
Prompt Library: Store prompts in Git with semantic versioning. Require review for any edits.
Audit Trail: Log every inference with a timestamp, input hash, model version, and output checksum. This record becomes your defense during an audit.
5. Practical Application: The Servos Approach
At Servos, reproducibility is part of our design pattern for Responsible AI in Government. We implement the "Reproducibility Stack" through:
Standardized Prompt Packs: Every AI module uses frozen, versioned prompt templates under Git control.
Deterministic Execution: Integrations run at fixed temperatures with schema-validated JSON outputs.
Audit and Replay: Every interaction logs model metadata, allowing auditors to "replay" a decision to verify it produces the same result.
Closing Thoughts
Determinism in AI isn’t about draining creativity from machines; it’s about anchoring that creativity to reliable, repeatable frameworks. In government and other high-accountability domains, reproducibility equals trust—and trust is the currency that will decide whether AI thrives or fails in public service.

Pat Snow serves as Vice President of State and Local Government Strategy at Servos, following his retirement as CTO of the State of South Dakota in June 2024. During his 28-year career in state government, Pat established South Dakota as a national leader in consolidated IT infrastructure and digital service delivery. At Servos, he continues to drive digital transformation in the public sector, helping agencies deliver more efficient and accessible services through the ServiceNow platform.